PlayDiffusion - Next-Generation AI Voice Inpainting Technology for Seamless Audio Editing
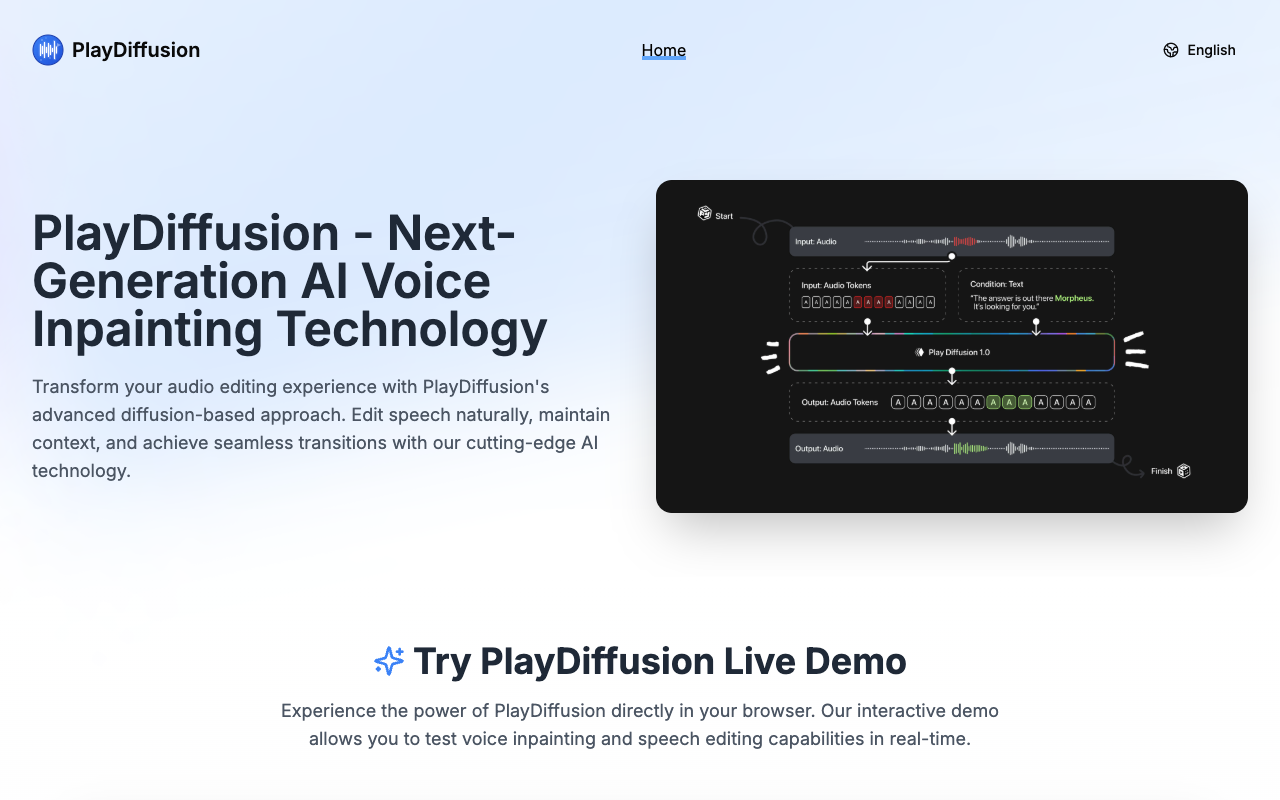
PlayDiffusion is a revolutionary AI voice model designed for inpainting and speech editing. With its advanced diffusion-based approach, it transforms your audio editing experience, allowing for seamless modifications while maintaining the natural flow of speech. Whether you’re a developer, audio engineer, or simply curious about voice technology, PlayDiffusion offers a powerful tool to enhance your audio projects.
The technology behind PlayDiffusion is groundbreaking. It utilizes a novel diffusion-based approach that encodes audio into discrete tokens, enabling precise modifications of specific audio segments. This means you can edit speech naturally without introducing discontinuities or artifacts. The model’s context-aware editing capabilities ensure that the surrounding audio remains intact, preserving the speaker’s characteristics throughout the editing process. This is particularly beneficial for applications in voice synthesis and speech inpainting, where maintaining the original voice identity is crucial.
One of the standout features of PlayDiffusion is its non-autoregressive architecture, which allows for audio generation at speeds up to 50 times faster than traditional models. This efficiency makes it suitable for real-time applications, where quick and high-quality audio modifications are essential. Additionally, PlayDiffusion is open-source, providing access to its source code and model weights on Hugging Face. This encourages collaboration and innovation within the community, allowing developers and researchers to contribute to the advancement of voice AI technology.
In conclusion, PlayDiffusion represents a significant leap forward in audio editing technology. Its advanced features and capabilities make it a game-changer for anyone looking to work with voice and audio. Explore the possibilities by trying out PlayDiffusion today at PlayDiffusion .