Seed-Coder - A smart code model that learns on its own
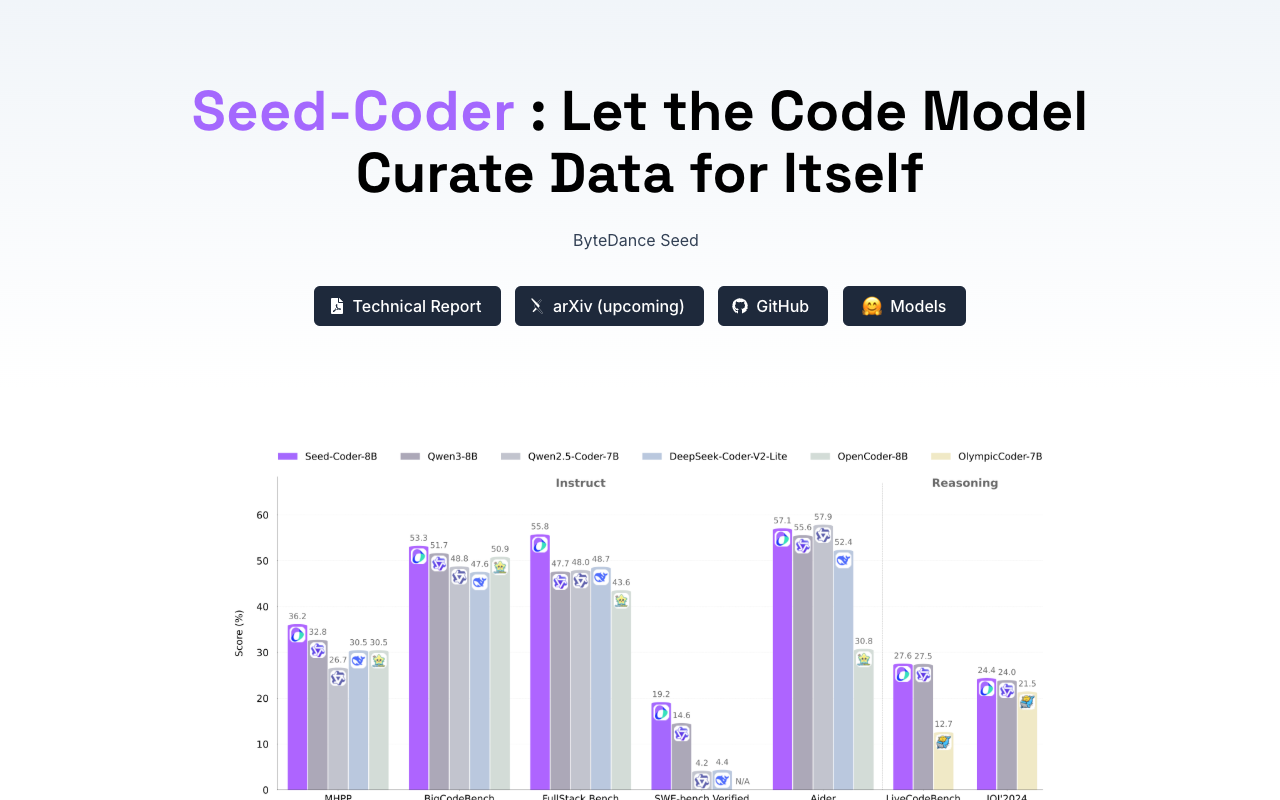
Seed-Coder is an innovative open-source code model developed by ByteDance, designed to automate the process of curating its own training data. This powerful model family operates at the 8B scale and includes base, instruct, and reasoning variants, showcasing remarkable performance across various coding tasks. By utilizing large language models (LLMs) instead of traditional hand-crafted rules, Seed-Coder minimizes the manual effort required for pretraining data construction.
The model’s architecture emphasizes transparency by providing detailed insights into its data pipeline. Seed-Coder effectively curates code from diverse sources such as GitHub, ensuring high-quality training data with minimal human intervention. This approach not only enhances the coding capabilities of the model but also promotes the evolution of open-source LLMs, showcasing the potential of LLMs in filtering and scoring code data.
Seed-Coder’s benchmark performance indicates that it surpasses many comparable models in solving complex software engineering tasks. Its instruct variant excels in predefined workflows and fully autonomous coding scenarios, while its reasoning variant demonstrates strong capabilities in competitive programming. As Seed-Coder continues to drive advances in code intelligence, it is set to empower a broader range of applications within the open-source LLM community.
You can learn more by visiting Seed-Coder .